Why do today’s gadgets feel so fast and smart? It’s not just because of stronger processors, it’s because they can now see and think on their own. For years, real visual intelligence existed only in powerful cloud servers. Such tasks included recognizing a face or spotting a tiny defect. But things have changed. With Edge Computer Vision, that intelligence now lives right on our devices. This shift is transforming everything. It changes how self-driving cars understand their surroundings. It also affects how your smartphone captures and edits photos in real time.
Edge Computer Vision brings together the smart image-processing power of Computer Vision and the fast, local computing of Edge AI devices. This mix supports real-time decisions to be made right where the data is created. It cuts down delays and keeps information more private. In this complete guide, we’ll explore how it works. We will discuss its main parts. You will also learn how models are optimized for edge devices. Finally, we’ll see how it’s being used in the modern world. Everything is explained in simple, clear language so you can easily understand each concept. Get ready to dive into the future of truly intelligent devices.
What Is Edge Computer Vision, and How Does It Work?
Picture this, you are trying to recognize a bird in your backyard. You wouldn’t send its photo to a huge library miles away, wait for them to analyze it, and get a reply an hour later. Instead, you’d instantly check your bird guide or open a bird app on your phone to find the answer yourself.
That quick, local action perfectly explains how Edge Computer Vision works.
Edge Computer Vision involves using deep learning and image recognition models directly on Edge AI devices. These are devices like cameras, smartphones, drones, or industrial sensors. They are utilized to analyze visuals in real time. Instead of sending large video files to a cloud server for processing, the device processes everything on-site. It does this right where the data is captured. This makes the process faster, smarter, and more efficient.
Cloud CV vs. Edge CV: The Speed Advantage
The fundamental difference lies in latency reduction and bandwidth optimization.
| Feature | Cloud-Based Computer Vision | Edge Computer Vision |
|---|---|---|
| Inference Location | Remote data center/server | Local device (the “edge”) |
| Data Sent | Raw, high-resolution video/images | Small outputs (e.g., “Person Detected”) |
| Latency | High (waiting for data upload + processing + download) | Extremely Low (near real-time, often <50 ms) |
| Privacy | Lower (Raw data must be transmitted) | Higher (Raw data never leaves the device) |
| Reliability | Dependent on network connection (internet) | High (Operates even if the internet fails) |
When inference happens locally, it cuts out the round trip to the server. Inference is the act of running the model to make a prediction.
The Science Behind Edge AI
Edge AI is not just a way to deploy technology, it mirrors how nature works efficiently. At its heart, this science focuses on creating smart systems. These systems think and act in a distributed way. They are just like intelligence spread across living networks.
Distributed Intelligence and the Latency-Energy Trade-Off
The main idea is simple, process data right where it’s created. Every time data travels over a network, it uses energy to power transmitters and adds delay because of latency. In continuous vision tasks, sending gigabytes of video every hour quickly drains both energy and bandwidth.
Edge AI solves this by working smart. Instead of sending everything to the cloud, it processes most of the data locally. This approach uses a bit more power on the device itself. However, it saves a huge amount of network energy and cuts down delay dramatically.
This is even more fascinating because it works just like the human brain. It is quick, efficient, and selective about what information it sends.
Why Edge Vision Matters Scientifically
Our brain doesn’t send every image we see to a single “cloud” center for analysis. Instead, it starts processing right where the action happens, in the retina and visual cortex. This quick, local decision-making is what lets you instantly dodge a ball flying toward your head. Edge Vision systems follow the same idea, making smart decisions locally and fast.
This local intelligence model is essential for:
- Guaranteed Real-Time Response: Necessary for life-critical systems where a delay of even 100 milliseconds can be dangerous (e.g., medical devices, drones).
- Robustness: Vision continues even if the network is flaky, which is common in remote industrial or agricultural settings.
How Neural Networks Mimic Human Vision Efficiency?
Modern lightweight neural networks like MobileNet work a lot like the Human Visual System. Our brain first processes visuals in low resolution, fast and local, and only activates the complex, energy-heavy regions when needed. In the same way, Edge Computer Vision models use smart structures. They use Depthwise Separable Convolutions to split big computations into smaller, efficient parts. This design mimics how our brain uses specialized pathways to process information quickly. As a result, these models deliver high accuracy. They use only a tiny fraction of the power that large, traditional models require.
Architecture of an Edge Computer Vision System
A functional Edge Computer Vision pipeline combines specialized hardware and software that work together seamlessly. It’s much more than just a camera connected to a server. It’s a complete system built for real-time intelligence and performance.
Components Explained Simply
A typical Edge CV system can be broken down into three logical layers:
1. Sensor Layer (The Eyes)
- Cameras: The primary sensor. These range from standard RGB (Red, Green, Blue) webcams to high-resolution, global-shutter industrial cameras.
- LiDAR/Depth Sensors: Used to add three-dimensional context, crucial for robotics and autonomous driving, as they measure distance and spatial relationships.
- Microphones/Other Sensors: For multimodal AI, pairing visual data with sound or temperature often provides richer context.
2. Edge Layer (The Brain)

This is the heart of the system where on-device inference occurs. The choice of the Edge AI device dictates the system’s power efficiency and speed.
- Microcontrollers (TinyML): Think ESP32 or small micro-boards. They run extremely lightweight models, often consuming only milliwatts of power. Perfect for simple tasks like basic object counting or anomaly detection.
- System-on-Modules (SoMs): Devices like the Jetson Nano (NVIDIA) or the Raspberry Pi family. These offer dedicated GPU or high-speed ARM cores, enabling complex object detection or segmentation models.
- AI Accelerators: Specialized hardware like the Google Coral TPU (Tensor Processing Unit). These are designed specifically to crunch the math of neural networks faster and with less energy than a general-purpose CPU.
3. Network & Cloud Layer (The Librarian)
- Model + Inference Engine: The software that takes the trained model and makes it run fast. Tools like TensorRT (for NVIDIA devices) or OpenVINO (for Intel) are the inference engines. They are responsible for neural network acceleration.
- Network Connectivity: Usually Wi-Fi, 4G/5G, or low-power protocols like LoRaWAN. Crucially, the network is used primarily for sending small results (metadata) and receiving model updates, not streaming raw video.
- Cloud Sync: The cloud is repurposed for data storage, long-term trend analysis, and model retraining—the large, non-real-time tasks.
Model Optimization in Edge Computer Vision
This is where the real magic begins. Large AI models trained on powerful server farms are massive, often hundreds of megabytes in size. They use 32-bit numbers and need a huge amount of processing power to run. But edge devices don’t have that kind of strength. Engineers apply model compression techniques to make it work. These techniques shrink the “server-sized” brains. As a result, they can fit and run smoothly inside small edge devices.
Quantization — Shrinking Precision Without Losing Accuracy
A deep learning model is trained on the cloud. Its weights and activations (the numbers it uses to calculate) are stored as 32-bit floating-point numbers (FP32). This provides high precision but requires significant storage and computational power.
Quantization is the process of reducing this numerical precision, usually from 32-bit floating point to 8-bit integer (INT8).
- How it Works: Instead of a wide, continuous range of numbers, you map them into a smaller set. Specifically, you “quantize” all the FP32 values into INT8 values.
- The Math (Simplified): Moving from FP32 to INT8 reduces the model size by 4 times. It dramatically speeds up calculation because integer math is far faster for most hardware.
- Real-world example: The popular object detection model, MobileNetV2, can be quantized to 8-bit integers. This quantization often achieves a 3-4 times speedup in inference time. It results in only a negligible drop in accuracy, often less than 1%. This transformation is what makes it a powerhouse for real-time mobile and edge applications.
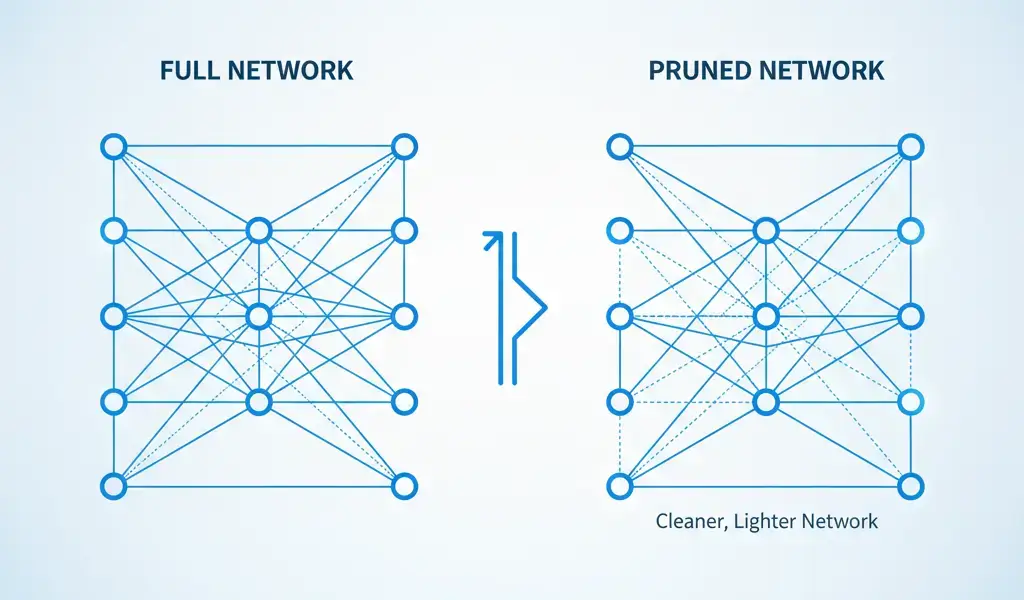
Pruning — Cutting Redundant Neurons Smartly
Neural networks are often “over-parameterized.” This means they contain many weights and connections. These elements contribute very little to the final, correct answer. Think of it like a dense tree, many branches are redundant.
Pruning is the technique of surgically removing these unnecessary weights and connections.
- Structured Pruning: Removes entire blocks, channels, or layers of neurons. This creates models that specialized hardware can process more easily. It is generally preferred for creating lightweight models because it doesn’t leave gaps.
- Unstructured Pruning: Removes individual, low-importance connections randomly. This achieves higher compression but can be harder for standard hardware to accelerate because the network structure becomes irregular.
Knowledge Distillation — Teaching a Smaller Model
This technique solves the trade-off between model size and accuracy in a clever way. You should not try to shrink a huge model after it’s trained. Doing so loses accuracy. Instead, you train a small model to mimic the outputs of a large, high-performing model.
- Intuitive Teacher–Student Analogy: The large, high-accuracy model is the “Teacher.” The small, fast, edge-ready model is the “Student.” The student is not just trained on the original labeled data (hard labels, e.g., “This is a cat”); it’s also trained to match the “soft targets” (the confidence scores and nuanced outputs) of the Teacher model. The Teacher, having learned more, guides the Student to generalize better than it would on its own.
- Equation for Distillation Loss: The student model’s training objective involves minimizing the standard classification loss. It also includes the distillation loss, which measures the difference between the Student’s output and the Teacher’s output.
Combining Techniques
The most effective Edge CV solutions typically use a combination of these methods:
- Start with Knowledge Distillation: Train a small student model guided by a large teacher.
- Apply Quantization: Convert the resulting small model’s weights and activations to $\text{INT}8$.
- Use Frameworks: Tools like TensorFlow Lite, PyTorch Mobile, and ONNX Runtime are essential. They act as the final conversion and runtime environment, ensuring the optimized model can run efficiently on the target Edge AI devices.
When to Choose Edge Over Cloud
Deciding whether to deploy a Computer Vision solution to the cloud or the edge is a strategic choice. It’s governed by strict, real-world constraints. You should choose the edge if your application’s requirements cross certain thresholds.
The Edge Decision Flowchart
Use this framework to guide your deployment choice:
| Factor | Edge Deployment Preferred | Cloud Deployment Preferred |
|---|---|---|
| Latency Threshold | Real-time response is critical (~100 ms) | Near-real-time or batch processing is acceptable |
| Privacy Sensitivity | Raw video/images contain PII (e.g., healthcare, facial data) | Data is anonymous or non-sensitive |
| Connectivity Reliability | Remote location, intermittent, or low bandwidth connection | Reliable, high-speed connection is always available |
| Device Cost (Per Unit) | Initial device cost is higher, but data transfer costs are low | Initial device cost is lower, but long-term data transfer is high |
| Model Size | Model can be aggressively optimized and compressed (e.g., TinyML) | Large, state-of-the-art models are necessary for high accuracy |
Example Scenario: Consider a smart traffic camera used to monitor illegal lane changes.
- Cloud Approach: It streams every minute of video to the cloud. By the time the cloud detects an infraction, the vehicle has already left the area. The system is slow and expensive due to bandwidth.
- Edge Approach: The camera runs a lightweight object detection model (like a quantized MobileNetV2) locally. The moment an illegal lane change is detected, it only sends a tiny alert: “Infraction: Car ID X at 14:35:01.” This is instant, saves bandwidth, and maximizes privacy.
For more in-depth strategic analysis on deploying complex AI systems, Edge AI Deployment Handbook for IoT offers excellent frameworks. These frameworks are useful for calculating the total cost of ownership (TCO) for both cloud and edge architectures.
How Edge Computer Vision is Revolutionizing Power, Energy, and Thermal Science
On an Edge AI device, power consumption is the ultimate constraint. These devices are often battery-powered or rely on Power over Ethernet (PoE), making every milliwatt count. The science here shifts from raw computational speed to energy efficiency.
Thermal Control in Continuous Inference
Running a neural network model, especially one for real-time video analytics, generates heat. This is the thermal science problem.
- Problem: Excessive heat leads to thermal throttling, where the device automatically slows down the processor to protect itself. This, ironically, hurts performance and increases inference time.
- Cruciality: For continuous operation (e.g., a security camera), managing heat is vital. This often requires passive cooling (heat sinks) or active cooling (small fans) for devices like the Jetson Nano.
Power Consumption and Duty Cycling
We can quantify the impact of Edge CV on a device’s runtime.
Small Calculation Example (Hypothetical):
Assume an edge device consumes:
- 5 Watts when running the FP32 model.
- 1 Watt when running the INT8 quantized model.
If the battery stores 100 Watt-hours:
- Battery Life (FP32) = 100 Wh / 5 W = 20 hours
- Battery Life (INT8 Quantized) = 100 Wh / 1 W = 100 hours
This 5 times increase in battery life clearly demonstrates why optimization is mandatory.
Efficient Scheduling (Duty Cycling): To save even more power, devices use duty cycling. The device only wakes up, captures an image, runs the inference, and goes back to sleep. For example, a wildlife camera might “wake” only when a motion sensor triggers it. This minimizes the time spent in the high-power inference mode.
Data Pipeline & Federated Learning on Edge
The problem with localized intelligence is that the model’s knowledge only extends to the data it sees locally. Federated Learning allows devices to learn collaboratively. It maintains the core benefits of the edge—privacy preservation.
Collaborative Learning Without Sharing Raw Data
Federated learning is a machine learning technique. It trains an algorithm across multiple decentralized Edge AI devices. These devices hold local data samples without exchanging the data samples themselves.
- Local Training: Each edge device uses its unique data to train an initial model copy. Device A, Device B, and Device C all perform this training locally. This training occurs locally and utilizes private data.
- Model Updates (Not Data): The device does not send the raw images or video. It calculates the changes (weights and gradients) needed for its model copy. These changes are tiny compared to the raw data.
- Secure Aggregation: The model updates from all devices are sent to a central server. The server averages these updates securely, creating a new, improved global model.
- Distribution: The new global model is pushed back down to every edge device. This process effectively gives each device the collective knowledge of all participants without ever seeing their private data.
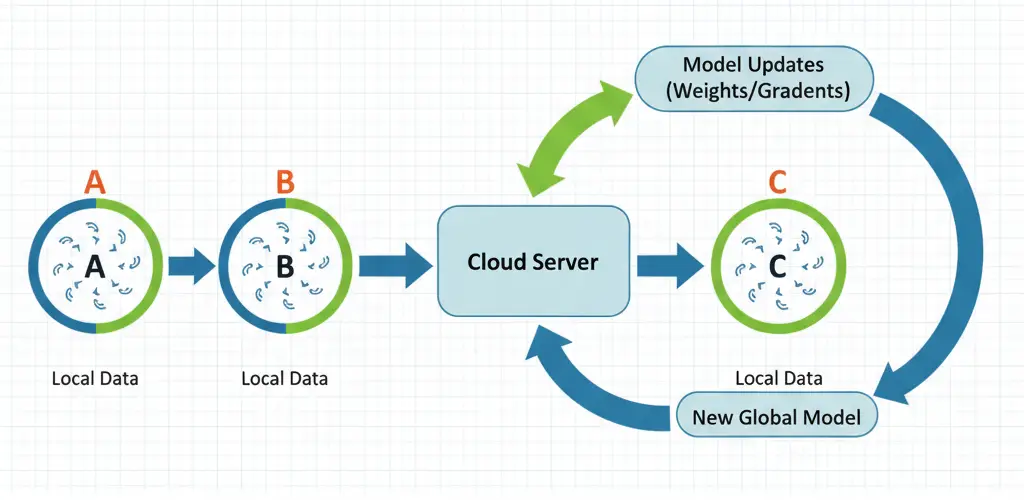
This process fundamentally changes the AI model deployment lifecycle. The devices become active learners, constantly refining their local intelligence, rather than static recipients of a single, central model.
Real-World Applications of Edge Computer Vision
The real power of Edge Computer Vision is evident in the transformative applications that require speed, reliability, and privacy.
Smart Cities
- Real-time Traffic Analytics: Cameras on traffic lights run object detection locally. They count vehicles and calculate flow. The system dynamically adjusts light timing to optimize traffic and reduce congestion. The data sent is simply “120 cars passed in the last minute.”
- Surveillance and Anomaly Detection: In airports or train stations, edge devices can immediately detect unauthorized items. They can also identify people in restricted areas. These actions trigger an alert instantly. This is faster and more reliable than streaming hours of footage to a remote monitoring center.
- Waste Management: Edge cameras on garbage trucks use image recognition to classify the type of waste in real-time. This helps municipalities ensure compliance. It also optimizes routing based on fill levels.
Healthcare
- Medical Imaging on Portable Devices: Edge processing enables field medical teams to perform initial diagnostics. They can use portable ultrasound machines or endoscopes for this purpose. The device can highlight areas of concern (like potential tumors) instantly. It guides the operator before the full image is sent to a specialist.
- Patient Monitoring: Wearable IoT camera systems or remote home monitoring devices can analyze patient behavior (e.g., fall detection, tremor analysis) locally, sending only a specific, privacy-preserving alert when a critical event occurs.
Industry & Automation
- Predictive Maintenance: Cameras on production lines use defect detection models to spot tiny cracks. They identify wear or misalignment on machinery in real-time. By catching issues early, the system can predict a potential failure, saving millions in downtime.
- Robot Vision: Autonomous warehouse robots rely on ultra-low latency Computer Vision to navigate, pick items, and avoid human collision. The vision processing must be nearly instantaneous for safe, high-speed operation.
Agriculture
Drones or ground vehicles use Edge inference on small on-board computers to analyze plants. They can identify pest infestations, nutrient deficiencies, or weeds. Then, they instantly trigger a precise application of treatment (precision agriculture). This approach saves resources and time.
Future of Edge Vision: Where Science Meets Next-Gen AI
The Edge Computer Vision revolution is just beginning. The future lies in making the edge smarter, more autonomous, and capable of running even more complex models.
Vision Transformers & Multimodal Models at the Edge
Traditional models for the edge were mostly Convolutional Neural Networks (CNNs). Researchers are now successfully shrinking cutting-edge architectures like Vision Transformers (ViTs). These architectures, which are usually massive and computationally demanding, are being adapted to run on edge devices. This transition promises to bring the superior long-range context understanding of ViTs to tiny devices. Similarly, multimodal models will process sight, sound, and text simultaneously. These models will become common on the edge. They will create truly comprehensive local intelligence.
Edge Devices Evolving with Neuromorphic Chips
The most radical scientific shift is toward specialized hardware. Neuromorphic chips are processors designed to mimic the structure and function of the human brain’s neurons and synapses. They process data in a fundamentally different way. This event-driven and highly parallel processing promises exponentially greater power efficiency and speed for AI tasks than current CPUs/GPUs. This hardware will fully enable the creation of truly decentralized, autonomous vision systems.
Predicted Shift: Decentralized AI Ecosystems
In the future, a network of devices will function as one giant, distributed brain. Instead of a single model running on one device, multiple small, specialized models will communicate with each other peer-to-peer. For example, a phone might run a lightweight face detector. It then passes the crop to a smartwatch. The smartwatch runs a highly specific sentiment model. This shift will create highly adaptable, redundant, and secure decentralized AI ecosystems.
Getting Started: Build a Simple Edge CV Project
Want to get your hands dirty and see Edge Computer Vision in action? The best starting point is an NVIDIA Jetson Nano or a Raspberry Pi with an AI accelerator.
Mini Tutorial: Object Detection on Jetson Nano using MobileNetV2
Here’s a conceptual flow to take a model from the cloud to the edge:
| Step | Action | Description |
|---|---|---|
| Baseline Model | Select a pre-trained MobileNetV2 model. | Use a model trained on a large dataset like ImageNet. |
| Optimization (Quantize) | Convert the model using a framework like TensorRT. | TensorRT is NVIDIA’s inference optimizer that performs quantization (FP32 to INT8) and kernel fusion for maximum speed on the Jetson’s GPU. |
| Deploy | Load the optimized model onto the Jetson Nano. | The inference engine handles the runtime. |
| Test & Record Latency | Run the model on a live video stream. | Measure the Frames Per Second (FPS) and the total inference time in milliseconds. |
Example Command:
# Assuming you have the TensorRT-optimized engine file (.engine)
import jetson.inference
import jetson.utils
# 1. Load the optimized quantized model
net = jetson.inference.detectNet(model="quantized_mobilenet_v2.engine", threshold=0.5)
# 2. Capture live video input
camera = jetson.utils.videoSource("csi://0")
# 3. Run Inference Loop
while True:
img = camera.Capture()
detections = net.Process(img)
# The 'detections' object is the fast, local output (e.g., location of a 'person')Expected Output Table (Comparison):
| Model Version | Device | Model Size | Inference Time (ms) |
|---|---|---|---|
| FP32 (Original) | Jetson Nano | 14 MB | 150 MB |
| INT8 (Quantized) | Jetson Nano | 3.5 MB | 45 MB |
The 3 times reduction in latency is the tangible win of Edge Computer Vision.
Resources and Datasets for Edge CV Researchers
If you want to move beyond simple demos and contribute to or apply the science, you need specialized resources.
Datasets for Lightweight Models
Standard datasets like COCO are too large for initial edge experimentation. Researchers often turn to optimized, smaller versions:
- COCO-lite: It is a smaller, more manageable subset of the massive COCO dataset. This subset is specifically curated to accelerate training and testing of lightweight models.
- VisDrone: Crucial for drone-based Edge AI applications, as it provides vision data captured from aerial platforms.
- EdgeImpulse Datasets: A platform that encourages the creation and sharing of highly specialized, small-footprint datasets for TinyML tasks.
- TinyImageNet: A smaller version of the massive ImageNet dataset, containing 200 classes and 100,000 images, perfect for prototyping.
Essential Tools and Frameworks
These tools are specifically built to solve the model optimization and deployment challenges of the edge:
- TensorRT (NVIDIA): A high-performance inference optimizer and runtime for deep learning specifically for NVIDIA GPUs (like the Jetson family).
- OpenVINO (Intel): A toolkit that optimizes models for running across various Intel hardware (CPUs, integrated GPUs, VPU accelerators like Movidius).
- TFLite (TensorFlow Lite): The official framework for running TensorFlow models on mobile, embedded, and IoT devices. It is the primary tool for quantization.
- Edge Impulse Studio: A comprehensive low-code platform for building and deploying TinyML models.
Conclusion
We have explored everything, from the basic science behind quantization to its real-world uses in smart cities and automation. The main message is simple: the future of AI is not locked away in the cloud anymore. It’s moving closer to where data is created, right at the edge.
Edge Computer Vision makes this possible by bringing faster processing, better privacy, and higher reliability to modern smart devices. When you understand how its architecture and optimizations work, you are no longer just watching AI evolve, you are part of it. This is your chance to create, innovate, and shape the future using these cutting-edge tools.
So, start experimenting. Build your own Edge CV projects. Keep learning about both the ethical and technical sides of putting AI directly into the world around us.
Recommended Resources for Curious Minds
If you are excited to explore the code and math behind building intelligent edge systems, check out the following resources. They are perfect for taking your understanding to the next level.
- Deep Learning with TensorFlow 2 and Keras by Antonio Gulli, Amita Kapoor, Sujit Pal
- The Artificial Intelligence Handbook for Investors, Entrepreneurs and FinTech Visionaries by Susanne Chishti
- NVIDIA Jetson AGX Orin 64GB Developer Kit
- Computer Vision: Algorithms and Applications by Richard Szeliski
FAQ Section: Edge Computer Vision
Edge in computer vision means processing visual data directly on local devices, like cameras or sensors, instead of the cloud. This enables faster decisions, low latency, and better privacy for real-time AI systems.
Edge AI offers faster and more private processing, while Cloud AI handles large-scale data and model training. The best setups combine both, Edge for instant insights, Cloud for deeper learning.
Edge detection helps find object boundaries in images. It’s essential for tasks like medical imaging, facial recognition, and self-driving cars to identify shapes and patterns.
Yes. Tesla cars process sensor and camera data locally using edge computing, allowing real-time driving decisions without cloud dependency, crucial for safety and speed.
Edge AI improves speed, security, and reliability by processing data near the source. It reduces latency, saves bandwidth, and works even without internet access.
References
- Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., & Adam, H. (2017). “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” arXiv preprint arXiv:1704.04861.
- acob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., & Kalenichenko, D. (2018). “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2704-2713.
- Han, S., Mao, H., & Dally, W. J. (2016). “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding.” International Conference on Learning Representations (ICLR).
- NVIDIA Corporation. (2024). “TensorRT Documentation: Developer Guide for High-Performance Deep Learning Inference.” NVIDIA Developer.
- Google Inc. (2024). “TensorFlow Lite: ML for Mobile and Edge Devices.” TensorFlow Documentation.
- Intel Corporation. (2024). “OpenVINO Toolkit Documentation.” Intel Developer Zone.
- Edge Impulse Inc. (2024). “Edge Impulse Documentation: Machine Learning at the Edge.”